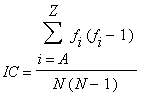
Cipher Analysis Techniques
One thing that I would like to present here are some simple analysis techniques that can be used to help when faced with unknown ciphers, or at least to get some ideas flowing. Suppose you have a cipher in front of you, method of encryption unknown and you wish to analyse it. Where can you start ? The simplest place to begin is by looking at the letters or symbols used in the cipher, and how many of each there are.
Frequency Analysis
Normal written English has very characteristic letter frequencies. Consider the following table, compiled from 10000 letters of literary English:
| E | 12.77% |
| T | 8.55% |
| O | 8.07% |
| A | 7.78% |
| N | 6.86% |
| I | 6.67% |
| R | 6.51% |
| S | 6.22% |
| H | 5.95% |
| D | 4.02% |
| L | 3.72% |
| U | 3.08% |
| C | 2.96% |
| M | 2.88% |
| P | 2.23% |
| F | 1.97% |
| Y | 1.96% |
| W | 1.76% |
| G | 1.74% |
| B | 1.41% |
| V | 1.12% |
| K | 0.74% |
| J | 0.51% |
| X | 0.27% |
| Z | 0.17% |
| Q | 0.08% |
Now if a cryptogram is a monoalphabetic substitution then it will have similar frequencies (albeit not the same letters) as the above. There is a measure called the 'Index of Coincidence' which can then be calculated to see how alike our cryptogram frequencies are to normal English. The formula for the index of coincidence is:
Normal written English has an IC of around 0.066. Entirely random text has an IC of around 0.038. A polyalphabetic cipher that uses a large number of alphabets would have an IC of around 0.038. Using two alphabets you would expect nearer to 0.052, and with 5 alphabets around 0.044. Of course with small amounts of ciphertext you will find variations in real values. Let's look at an example - the crypt from the substitution page:
juww tdru mdh zpiu fdwiut gzkf fhqfgkghgkdr skazuc prt gzu jdct gzpg mdh ruut vdc gzu prfjuc kf pwazpqug
Frequency counts are as follows:
| letter | count,f | f*(f-1) |
| a | 2 | 2 |
| b | 0 | 0 |
| c | 4 | 12 |
| d | 7 | 42 |
| e | 0 | 0 |
| f | 6 | 30 |
| g | 9 | 72 |
| h | 4 | 12 |
| i | 2 | 2 |
| j | 3 | 6 |
| k | 5 | 20 |
| l | 0 | 0 |
| m | 2 | 2 |
| n | 0 | 0 |
| o | 0 | 0 |
| p | 6 | 30 |
| q | 2 | 2 |
| r | 5 | 20 |
| s | 1 | 0 |
| t | 5 | 20 |
| u | 11 | 110 |
| v | 1 | 0 |
| w | 4 | 12 |
| x | 0 | 0 |
| y | 0 | 0 |
| z | 7 | 42 |
| Total | 86 | 436 |
And we have the sum equal to 436, which we need to divide by 86*85 for the IC, giving an IC of 0.060, which is close enough to 0.066 to make us think of monoalphabeticity.
You should also note from the table at the top of this page that written English contains around 40% vowels, a useful fact in figuring correct dimensions for columnar transpositions - seek a layout which has closest to the 40% vowel distribution for each column.
For a polyalphabetic crypt like Vigenere you will find that IC is normally between these values and is less as the keylength increases. If you suspect a simple polyalphabetic crypt like that then you can calculate the IC of every second letter, every third letter, etc until you find higher values. In fact this is how programs like vigsolve work.
Sometimes you may find that the IC is higher than 0.066, and a much higher value normally comes about from a high frequency presence of one or two characters. The IC of text where spaces have been encrypted for example will be higher since spaces are roughly 20% of characters. IC in this case would be nearer to 0.082. A high IC can also point to redundant or null characters or an underlying numerical system.
Out of interest, Friedman gives an IC of 0.0667 for English, 0.0778 for French, 0.0762 for German, 0.0738 for Italian and 0.0775 for Spanish.
Repeats and Contacts.
Repeats are simply repeated pieces of ciphertext, how long are the repeats, and how far apart are they ? This can help in determining the keylength of a polyalphabetic cipher. When I say how far apart I mean count from the start of the first occurrence of the repeat to the start of the second occurrence of the repeat.
By contacts I mean for each different character in the cryptogram, what characters appear before it, and what characters appear after it. This can give you some valuable insights into the cipher. Is 'e' always followed by 'f' ? Do some characters interact with many others ? In English vowels tend to contact many different characters, and often contact low frequency characters. It helps to write out contact tables, showing for each letter those letters that occur before it and those that occur after.
Taking the substitution example again:
| ijqruz | u | cgtuw |
| fhkpu | g | hkz |
| fjkmtv | d | chrw |
| ag | z | kpu |
| kqr | f | dghj |
| z | p | giqrw |
| kw | a | z |
| du | c | t |
| dfg | h | gq |
| pw | i | u |
| f | j | du |
| gsz | k | adfg |
| m | d | |
| hp | q | fu |
| dp | r | ftu |
| s | k | |
| cru | t | d |
| v | d | |
| dpuw | w | aiw |
I have placed the six high frequency letters at the top of this table (u,g,d,z,p,f). In fact these letters are e,t,o,h,r,s.
In general, the following points should be kept in mind:
See Gaines for more pointers on identifying individual letters from contact and frequency considerations alone.
Kappa test.
The Kappa test is a test of coincidence. Recall the 0.0667 IC value. If you have two pieces of English text and superimposed them against one another then for 1000 superimposed characters you would expect 66 or 67 coincidences between them. This is important because suppose you have two ciphers and suspect that they were encrypted with the same system and key - either monoalphabetic substitution or polyalphabetic substitution. If you superimpose them and count the number of coincidences, then the Kappa test basically tells you whether your suspicions are probably right or not. If the coincidences were merely random then you would only expect 38 or 39 coincidences in 1000 characters.
Friedman, in Military Cryptanalysis Part III, gives a good example of the application of the Kappa test if you wish to look into it further. He basically considers aligning four vigenere type messages encrypted with a very long key, used from different starting points.
The Chi test.
Suppose you have two frequency distributions and you wish to align them in the best possible way. This can happen whilst solving a polyalphabetic system where one alphabet is a shift of another alphabet and by aligning the two you can combine them into an easier to solve monoalphabetic substitution. This is the basis of solving a vigenere that has a mixed cipher alphabet - align the alphabets and reduce the whole problem to that of a monoalphabetic substitution. Basically you have two sets of frequency tables (see the one at the top of the page), and there are 26 ways to line them up together. The chi test can be used to find the best alignment. For any sample alignment, simply multiply the frequencies together and add them up, divide this by the length of each ciphertext. The resulting value is your chi value. In fact since you are only dividing by a constant you simply need to multiply the frequencies for each letter together and add these up:
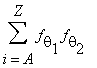
Probable Words and Pattern Matching.
An essential part of cryptanalysis involves having a number of probable words in mind, and identifying plausible positions for probable words to occur. If you want to know just how valuable a probable word attack can be than check out my solution to Zero-coders crackme 11. I cracked 64 bytes of encrypted text that had been encrypted with a 16 byte key. The probable word that I use to do this was 'Congratulations'. Many challenge sites have predictable probable words - congratulations, well done, good job, answer, solution, keyword, password, the solution is, the answer is, you will need, next level, rankup script,.... Whenever you have problems solving a level written by someone I recommend reviewing other levels by that person, and taking note of their use of language.
Another major attack is that of 'pattern matching'. The classic crypt 'dlldllfcdofmc omcftro.' is easily solved through pattern matching against a dictionary file. Observe the unusual beginning of the first word 'dlldll...'.